We are now DeepHealth
DeepHealth is RadNet's health informatics portfolio designed to dramatically drive efficiency and transform radiology’s role in healthcare. Previous Quantib products are now part of Saige, Deephealth's clinical AI offering.
Read the statement or visit our new website to discover more about our vision and our entire product protfolio.

Our AI Radiology Software
Our AI solutions are FDA-cleared, CE-marked and vendor neutral. Their easy integration with PACS makes them integrate seamlessly into radiologists' workflows.
Quantib® Prostate
.png?width=1359&height=500&name=QPR%203.1%20-%20PSAD%20step%20(fitted%20to%20screen).png)
The AI software that supports radiologists' prostate MRI reading workflow with AI-driven segmentations of the prostate and suspicious ROI, integrated PSA density calculation and PI-RADS scoring support.
Quantib® Neurodegenerative
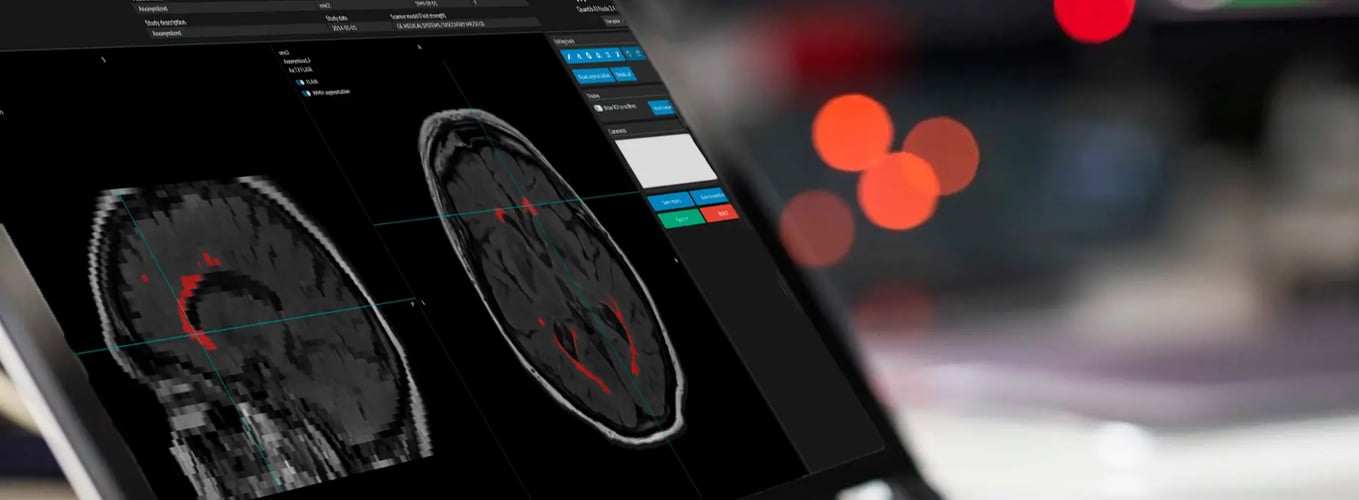
The AI software that enables radiologists to monitor brain atrophy and track white matter hyperintensities development through single-time-point and longitudinal analyses that include the segmentation and volume quantification of brain structures and WMH.
Discover more about AI and how it can help you advance radiology forward
Articles

Read our expert insights on AI, prostate cancer, neurodegenerative diseases, radiology and much more.
Read the articles
Published evidence
Find a list of all available published research that has evaluated one or more of our AI solutions.