Segmentation of MRI and CT images into the available tissues and structures plays a crucial role in quantification, both in medical research and clinical practice. This segmentation can be done manually, which is very time intensive and subject to intra- and inter-observer variability. Radiology software in the form of segmentation algorithms can be of great help, speeding up the process and creating objective, repeatable measurements.
In prostate cancer, for example, medical image segmentation and quantification of tissue volume is of great importance for both diagnosis and therapy. Here, an accurate segmentation of prostate tissue is required for taking biopsies and planning focal therapy. For Alzheimer’s disease, segmentation of brain tissue volume (e.g. for quantification of hippocampus volume) enables atrophy tracking and as such, supports early diagnosis.
Machine learning and its challenges in radiology AI
Automatic segmentation is gaining more and more attention for a large variety of applications. Most techniques developed for medical image segmentation nowadays are based on supervised machine learning. Here, a segmentation framework is trained based on examples of manually segmented images, the so-called training images. After training this framework, it can be used to segment a new image, called the test image.
These methods usually assume that data used for training is representative of the test data that is to be segmented. As a result, methods generally perform well if training and test data are from the same scanner (same brand and model), are obtained with the same scanning protocols and parameters, and consist of subjects with the same characteristics (age, sex, disease, etc.). However, in case of differences between training and test data, the performance of these methods often deteriorates. In medical research and clinical practice, this is a big impediment, since used images are often from different scanners, scanning parameters, or contain different patient groups.

How can transfer learning help in radiology AI?
A potential solution to this problem is transfer learning. Transfer learning is a sub-field of machine learning that comprises techniques coping with certain differences between training and test data. In her PhD research, Van Opbroek studied different approaches to transfer learning and their value for segmentation of MR brain images. Her methods aim to perform well on data from different datasets, scanned with different scanners, scanning parameters, and comprising different patient groups. The focus lies on whole-brain segmentation, brain-tissue segmentation, white-matter-lesion segmentation, and hippocampus segmentation, but the presented methods can also be applied to other medical image segmentation tasks.
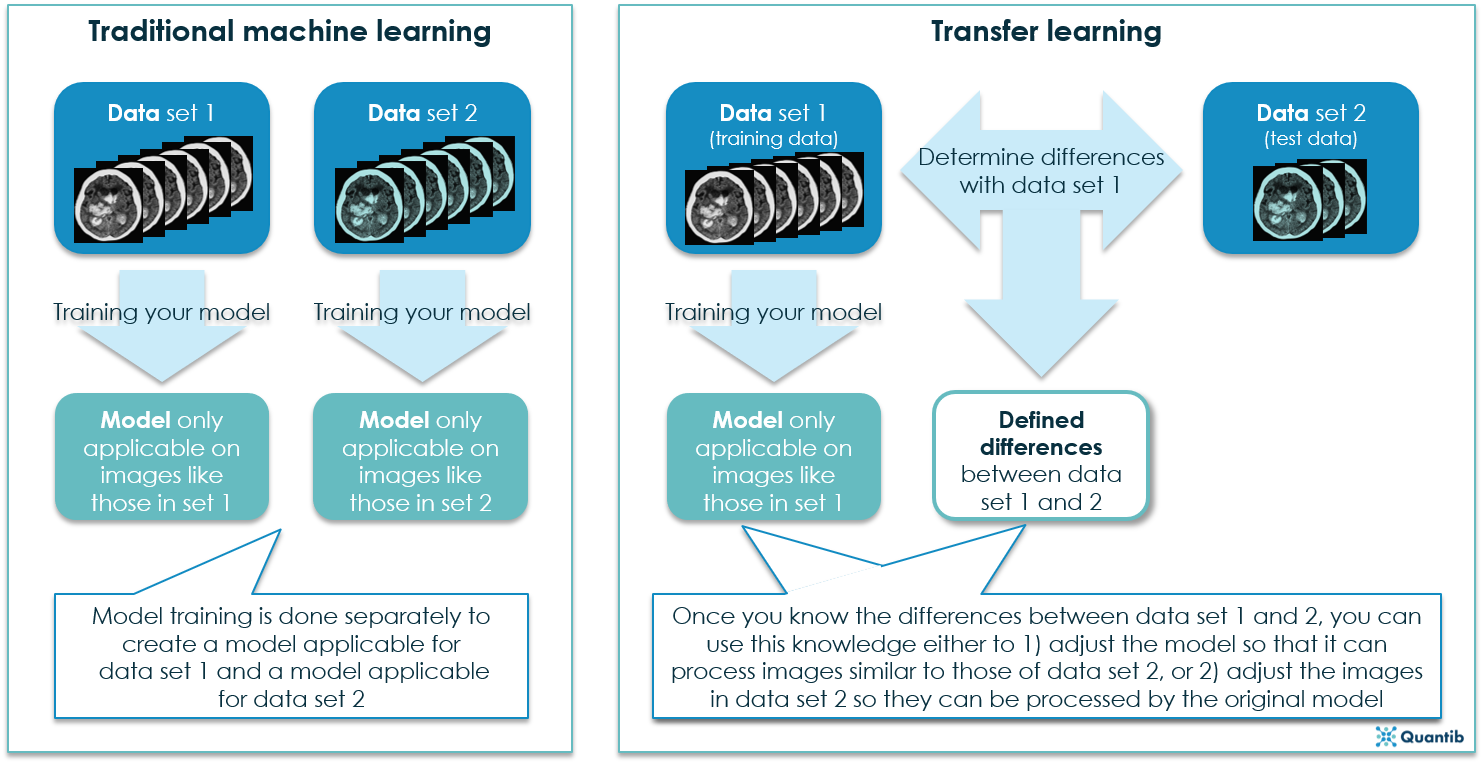
There’s more than one way to skin a cat in radiology AI
Three different situations were investigated with availability of different types of data. First of all, a setting where the model is trained on a training set that also contains a few images (or fragments) from the test scanner. Secondly, a setting where the model is trained on a training set that contains only images obtained with different scanners or settings than the test set. In both these settings, transfer learning algorithms have been proven to be able to bring large improvements in performance over classical non-transfer algorithms. In practice, the second setting might be especially interesting, as it would allow for the development of algorithms suitable for a wide range of scanners, without having images of all scanners available for algorithm development.
Third of all, Van Opbroek studied a setting using scan-rescan images (without manual segmentations) of the same subject on two different scanners (the training scanner and the test scanner). A method was developed that can use these scan-rescan images to map the manually segmented training images to the appearance of the test scanner. This way, the training images from different scanners can be used to train a segmentation framework on images from different scanners.
What can we conclude?
Data heterogeneity still is one of the main problems when applying artificial intelligence methods in large-scale clinical and epidemiological studies; methods such as transfer learning can be of great value here. We think transfer learning is a promising technique for the handling of differences in biomedical images and could greatly increase the applicability of medical image analysis techniques.
This article was based on the PhD thesis “Transfer learning for Medical Image Segmentation” by Annegreet van Opbroek. Curious for more information on Transfer learning? Check out the complete thesis.
