The training of neural networks typically requires large amounts of data. The more examples your network sees during training, the better it can learn to recognize varying representations of a disease. Consider training a network to automatically segment brain tumors on MRI scans. Ideally, you would like to train your network with a combination of small tumors, large tumors, and tumors in the various anatomical regions of the brain, so that the network can learn to recognize the underlying features of each of these representations. However, such a varied set of brain images is often hard to obtain.
Why is it so hard to get healthcare data, such as medical images?
Large medical datasets, existing of medical images, for example, are not easy to come by for various reasons. Firstly, most data is not accurately labeled, if labels are available at all. We should aim to train neural networks using annotations that are made by the best radiologists in the business, so that the networks can capture their knowledge and expertise. Unfortunately, manually annotating medical scans is rather time consuming. Hence, clinical experts typically provide only small datasets.
Secondly, sharing clinical data has become increasingly hard in the past years, due to patient privacy laws that are getting evermore strict. Although it is important to preserve the anonymity of the patient, it hampers the sharing of data between institutions. Centers, therefore, have a harder time combining their datasets to arrive at numbers that are meaningful for applying deep learning techniques. As a result, typical medical imaging datasets rarely exceed 500-1000 patients. Compare these numbers to those of the ImageNet project1, looking to classify everyday objects in pictures (‘dog’, ‘cat’, ‘hotdog’). ImageNet has over 14 million (!) hand-annotated examples available for training.2,3 Additionally, the ImageNet examples contain additional information in the form of colors, which can be utilized by the network in object detection. Information in medical images on the other hand is, most of the time, solely presented in a single channel (i.e., black-and-white), forming a bigger challenge for training neural networks.
Finally, although automating run of the mill cases using artificial intelligence can save a lot of time, we would also like AI to assist in the diagnosis of rare diseases. If a clinic only sees a small number of such patients yearly, it may take many years to arrive at a dataset large enough to facilitate deep learning strategies.

Have no fear! Image augmentation is here!
So, data is important, and getting it is hard. Luckily, machine learning scientists have developed Image Augmentation strategies, which can be used to trick the network into thinking we have more training examples at our disposal than we actually have. So, what is image augmentation? In brief, image augmentation means you apply randomized alterations to your data, thereby increasing the amount of variability in the dataset. For example, if your total dataset comprises 100 MRI images of the brain, and you apply 3 random alterations to each image, this already gives you 400 medical images available for training.
6 ways to implement image augmentation
So what exactly do we mean by ‘randomized alterations’? What do you need to do to your image to augment it? Below, we provide 6 examples of different image augmentation strategies.
1. Translating medical images
One of the simplest operations you can perform is translation, which is nothing more than shifting the region of interest, with respect to the center of your training image. Adding such augmentations to your dataset may help your network to better pick up shifted features.
2. Rotating medical images
Another strategy is rotating the training images by a random amount of degrees. This way, the augmented images may better resemble patients that were scanned under a small angle.
3. Flipping medical images
Many anatomical structures are symmetrical - take the brain and kidneys, for example. Medical images containing symmetrical features are ideally suited for augmentation using randomized flipping, through which the image information is mirrored horizontally or vertically. This also prevents the network from favoring features present in one side of the organ, while the disease might just as well have been located on the other side.
The 3 techniques discussed so far are examples of rigid augmentation techniques. This means that shapes in the image itself remain unchanged and that the image is merely shifted with respect to its original location. See the examples in Figure 1. This preserves the original image features well. The 3 following augmentation examples deform the image in a more extreme way.
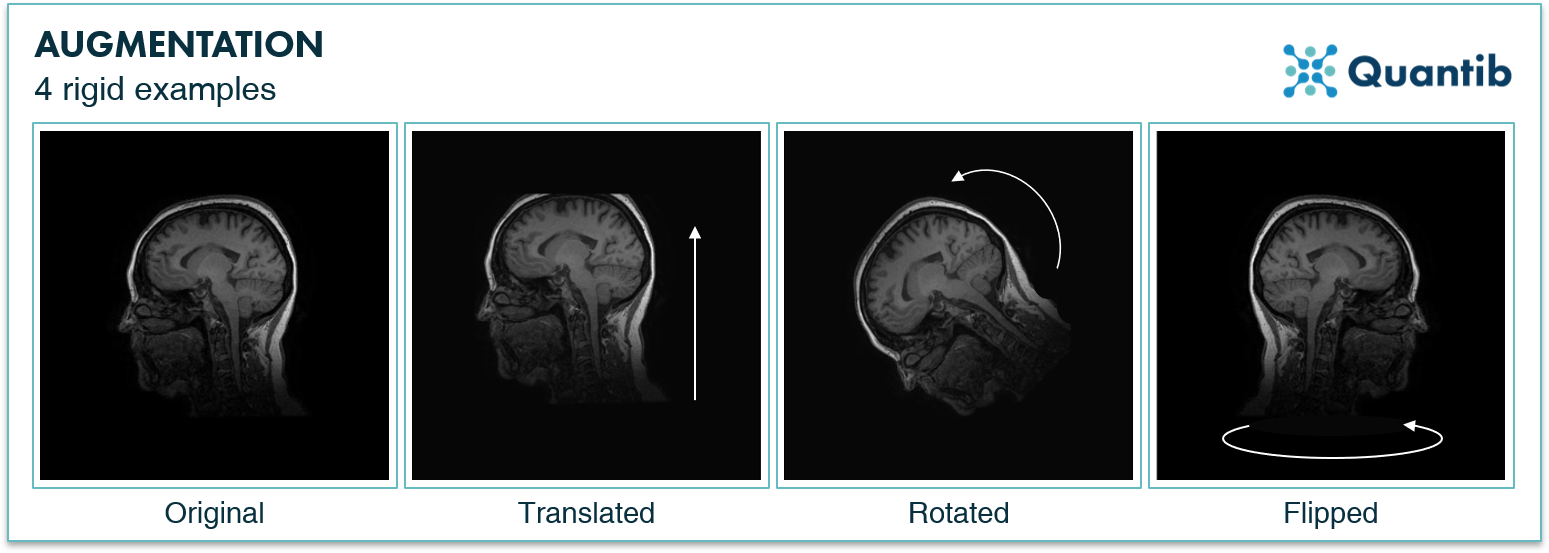
Figure 1: 3 rigid examples of image augmentation: translation, rotation, and flipping.
4. Stretching medical images
The same anatomical structures can present themselves differently between different scans. The total brain volume, for example, can vary strongly in size between patients. Image augmentation in the form of randomly zooming in and zooming out can add invariance to such variations. If the ratio between the horizontal and vertical augmentations is not kept constant, this stretches the image - adding even more variation. Note that it is important not to add augmentations that are unlikely to occur in original scans. For example, augmenting a brain MRI image so far that it results in a brain volume of over 2 liters will most likely confuse your network. Examples of image augmentation through stretching are shown in Figure 2.
5. Shearing medical images
Let’s say we do not stretch the image in only one direction, but we take the top of the image and move it to the right and take the bottom of the image and move it to the left. In this way we stretch the image in two opposite directions at the same time. This is called shearing. The last frame in Figure 2 shows an example.
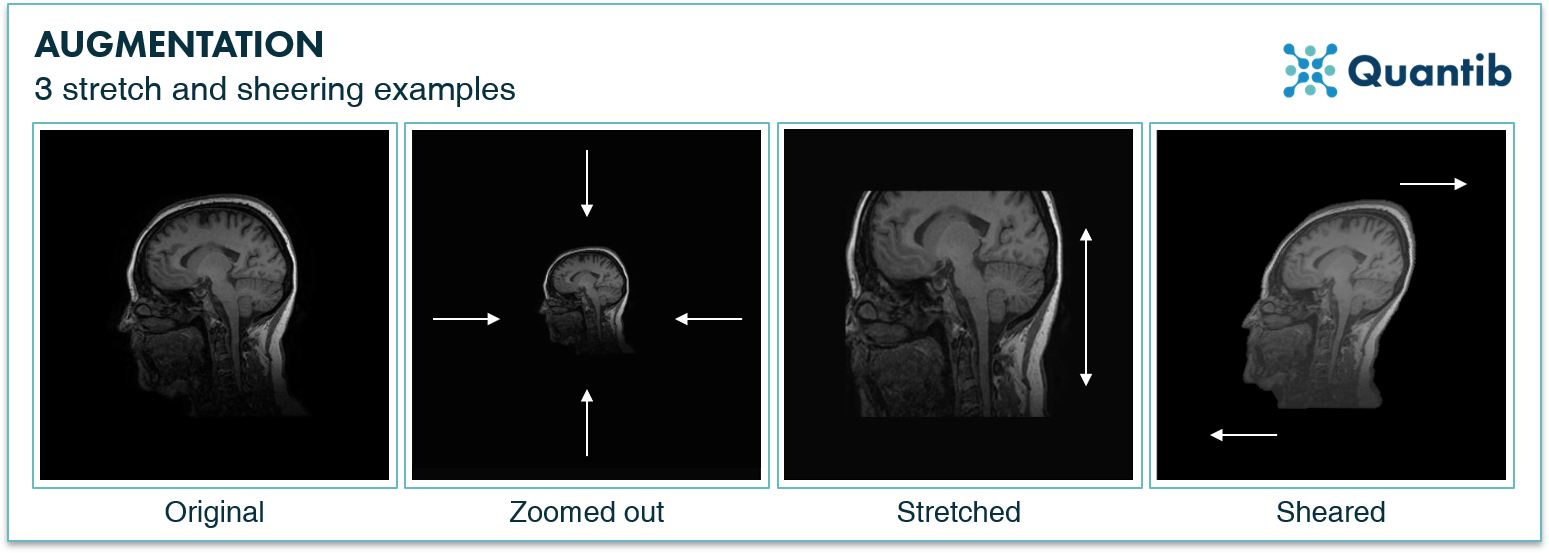
Figure 2: 3 examples of stretched image augmentation: zooming in or out, and stretching in one direction.
6. Elastic deformation of medical images
The first 5 techniques we discussed are known as linear augmentation. One of the more extreme forms of augmentation is called elastic deformation. It is similar to stretching, however, with more freedom. Elastic deformation allows you to change the image almost like kneading a stress ball. See Figure 3 for a visual illustration. One should be careful when applying this strategy as it is easy to overdo it, resulting in almost unrecognizable training images.
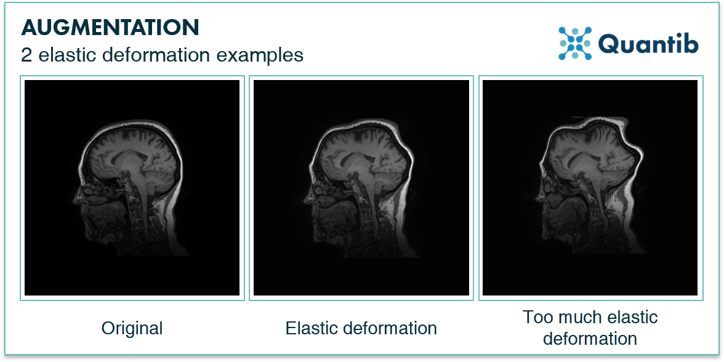
Figure 3: Augmentation can also be accomplished by applying elastic deformation.
7. Contrast augmentation of medical images
Our last image augmentation example is a bit different from the previous 5. Medical images that are obtained using equipment from different manufacturers may present variations in image intensity. To ensure that the trained network is robust for such intensity differences, contrast augmentations can be applied to the training data. These augmentations are performed by applying a random shift to the histogram of the gray-scale intensity values. See Figure 4.

Figure 4: Changing the contrast level of an image is also a form of image augmentation.
What are image augmentation best practices?
Now that we have explained various image augmentation strategies, the question arises how we can best apply these techniques. Simply expanding your original dataset by adding a number of augmentations to each medical image is the most straightforward approach. However, there is still a chance that the network will, at some point, begin to recognize features specific to this dataset, resulting in overfitting. A more sophisticated approach is, therefore, to use a generator, a specific algorithm that creates the augmented images on the fly. While you are training, this generator passes each of the training examples to the network, but each example is first augmented by the various strategies outlined above. By randomizing the type and magnitude of augmentation for each sample, a generator provides your network with vastly different combinations of data augmentation than you could do when you create augmentations manually. This exposes your network to even more different training examples, which typically improves algorithm performance.
We found the holy medical data grail! Or did we?
Should the augmented medical images still resemble the original data? Can you augment images too far, exceeding normal variations that are present in medical images? Experts do not seem to agree on this. Some say that heavy image augmentation causes the network to better learn general features, such as shape and curves that represent the boundaries of the anatomical structures, rather than focusing too much on specific features of individual images. Especially the first layers of neural networks often search for basic image features, which are preserved even when strongly augmenting. In general, performing linear augmentation is a safer approach, as it is better at preserving the image features present in the original image. Finally, although augmentation strategies are great for artificially increasing the amount of variation in your dataset, it should be noted that nothing beats accurately annotated medical scans.

Bibliography
- ImageNet. Available at: http://www.image-net.org/.
- Markhoff, J. Seeking a Better Way to Find Web Images. (2012). Available at: https://www.nytimes.com/2012/11/20/science/for-web-images-creating-new-technology-to-seek-and-find.html.
- Reynolds, M. New computer vision challenge wants to teach robots to see in 3D. (2017). Available at: https://www.newscientist.com/article/2127131-new-computer-vision-challenge-wants-to-teach-robots-to-see-in-3d/. (Accessed: 25th May 2019)