It is important to understand the role of AI bias in healthcare. As artificial intelligence (AI) applications gain traction in medicine, healthcare leaders have expressed concerns over the unintended effects of AI on social bias and inequity. Artificial intelligence (AI) software can help analyze large amounts of data to improve decision making. More and more, we come to rely on these algorithms for different kinds of purposes. It is, therefore, essential that their results are reliable. Unfortunately, this is not always the case. There are many examples of erroneous results of AI algorithms which are, more often than we would like, caused by biases. Even big companies such as Amazon, bust themselves using biased algorithms every once in a while. In 2015, Amazon tried to train an algorithm to rate suitable candidates for job vacancies based on previous selections. The result? An algorithm that gives high ratings to male candidates, because these were most often selected in the past, and lower ratings to candidates with a “less familiar” profile, such as women. The algorithm was trained on biased data, hence, biased results were to be expected.1
Though biased algorithms should always be avoided, there are circumstances in which it is no less than crucial, such as healthcare. However, it is not always perfectly clear when an algorithm is biased and when it is not. To develop a better understanding of the risks that biased algorithms bring to healthcare, we will explain the phenomenon of bias in more detail and discuss a few examples.
What exactly is AI bias in healthcare and why is it important to deal with?
Bias is trickier than most people think. Yes, bias in an algorithm is bad, but when exactly is an algorithm biased? It is often described as a particular trend or tendency in an algorithm to return a certain answer, but what if you are developing an algorithm that is supposed to classify brain tumors and it strongly favors the answer “non-malignant” over “malignant”? This is probably because, statistically, non-malignant brain tumors are more prevalent than malignant ones.2 Hence, if you used a representative dataset for algorithm training, you should actually be worried if the algorithm did not favor non-malignant. This is not bias. It is something we are aiming to achieve. We only call it bias if the algorithm is skewed towards an answer which is considered erratic. So if your algorithm is more likely to classify a brain tumor as non-malignant while you’re using it for a patient group for which you know they are more likely to have a malignant brain tumor, then you’re dealing with a bias. Be aware that this means an algorithm will be biased depending on how it’s trained and how it’s applied.
To better understand this difference between an algorithm that does what it is supposed to do and an algorithm that is biased, we will discuss 3 examples of bias in a clinical context.
AI bias in healthcare example 1: detecting early Alzheimer’s using speech data
Some time ago, a Canadian company called Winterlight Labs developed auditory tests for neurological diseases. Their software registers the way you speak, analyzes the data, and tells you whether you might have early-stage Alzheimer’s disease. However, the developers used a training dataset containing speech samples only from native English speakers. As a result, the algorithm may interpret pauses and differences in pronunciations among non-native English speakers as markers of a disease.3
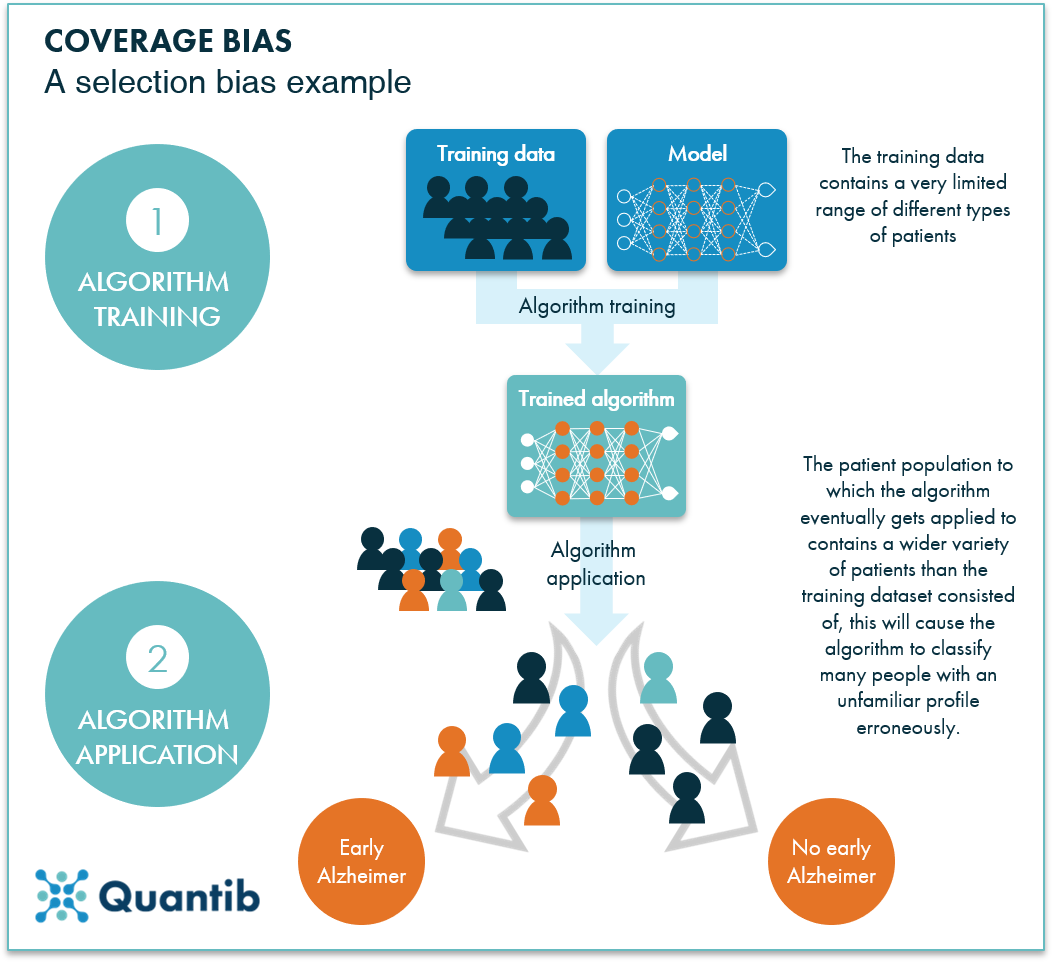 Figure 1: An example of coverage bias: the algorithm gets trained on a dataset containing a specific type of patients, and applying the resulting algorithm to other types of patients can result in erroneous results. The algorithm has not been able to learn the details of a wider range of patient types.
Figure 1: An example of coverage bias: the algorithm gets trained on a dataset containing a specific type of patients, and applying the resulting algorithm to other types of patients can result in erroneous results. The algorithm has not been able to learn the details of a wider range of patient types.
What can we learn from this example of AI bias in healthcare?
This type of bias is called a coverage bias, which is a subtype of selection biases.4 When training an AI algorithm, it is extremely important to use a training dataset with cases representative for the cases the trained algorithm will be applied to. In healthcare, this often comes down to having your training dataset containing subjects that are representative of the patient population of the hospital where the algorithm will be used. Using a training set with a very different distribution of types of patients from the population to be analyzed, will result in a selection bias. On the other hand, this type of bias links directly to the “it depends on how it is applied” remark made earlier. If you plan to use your algorithm on a population of solely males, there’s no harm in training the algorithm on data from males. Just a crazy example: if you want to detect prostate cancer, you are not going to include scans of the female pelvic area, are you? Just make sure the training data matches, to a certain extent, the data on which you will eventually apply the algorithm.
AI bias in healthcare example 2: diagnosing skin cancer on different types of skin
In addition to the training set being representative of the population, it is important that the training set is balanced. A Stanford University study claimed that an AI system performed comparably to a trained dermatologist when diagnosing malignant skin lesions from images. The dataset the researchers used, however, consisted of mostly Caucasian skin samples. White people suffer from skin cancer more often, so there simply was more data available for that skin type. Even though an algorithm trained on this data will be more likely to have to diagnose people with light skin, it still needs to learn about other skin types as well. Otherwise, the AI algorithm will be biased towards lighter skin and is not suitable for clinical use in a hospital with a patient population with a wide variety of skin types.5
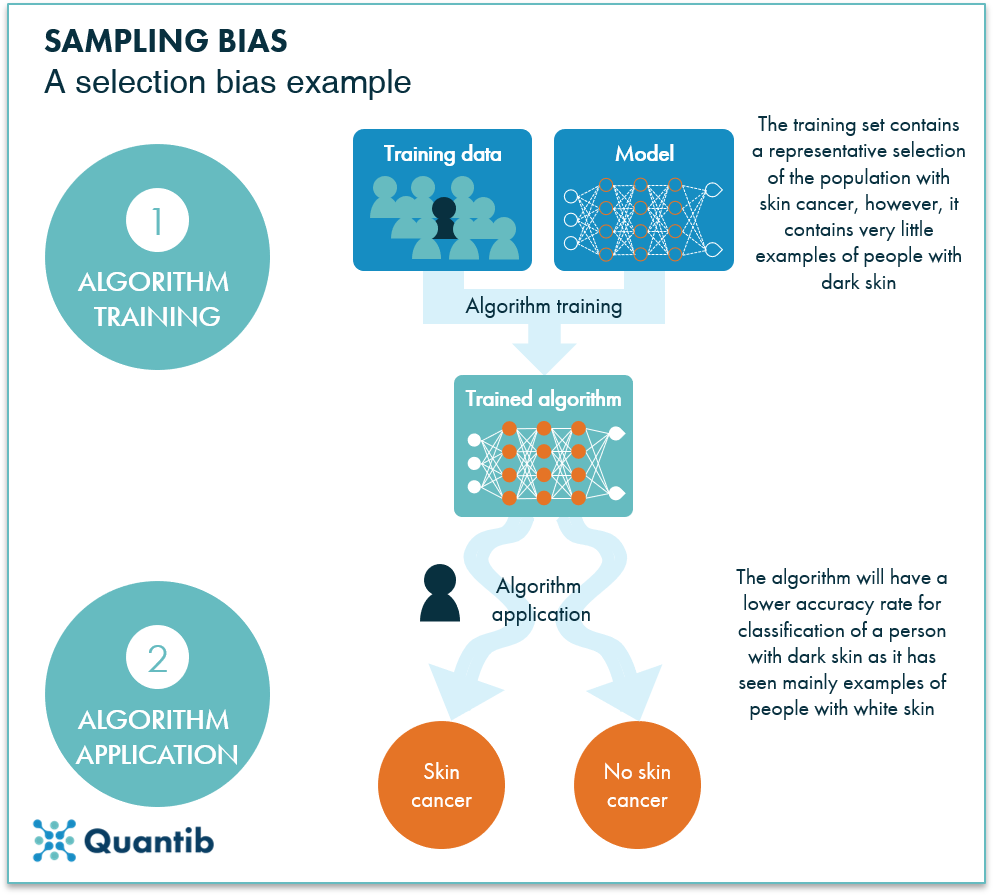 Figure 2: An example of sampling bias: the algorithm was trained on a patient dataset containing a very small amount of a certain patient type. The resulting algorithm will have great difficulty classifying cases of this specific patient type, because it never had a chance to learn the specifics of this group.
Figure 2: An example of sampling bias: the algorithm was trained on a patient dataset containing a very small amount of a certain patient type. The resulting algorithm will have great difficulty classifying cases of this specific patient type, because it never had a chance to learn the specifics of this group.
What can we learn from this example of AI bias in healthcare?
It is not enough to just have a dataset that is representative of the patient population you plan to apply your algorithm to. You need to make sure the minorities in your patient population are well represented in your dataset as well. This is also an example of a selection bias. To be more precise, we call this type of bias a sampling bias.4
AI bias in healthcare example 3: predicting length of hospital stay
In another case, an algorithm was developed to predict the length of hospital stay to identify patients who are most likely to be discharged early. The algorithm used clinical data to come to a recommendation, and patients that would most likely be discharged early would get a case manager assigned. However, adding zip code to the training data strongly improved the accuracy of the algorithm. It turned out that patients living in poorer neighborhoods were more likely to have a longer length of stay. If this plan would have been set in motion, the case managers would have been assigned to more wealthy people, while the underprivileged ones could have really used the help.6
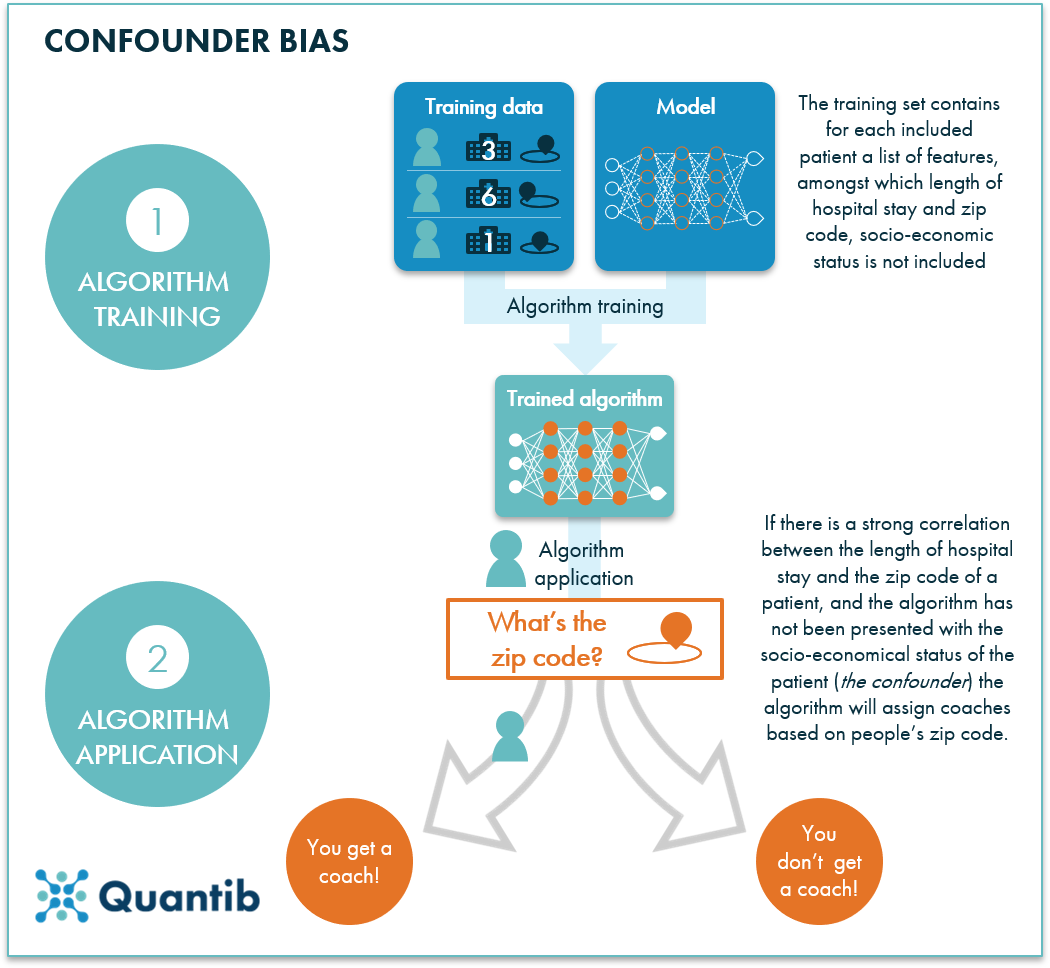 Figure 3: An example of confounder bias: the training data used for this algorithm contains multiple features per patient, including length of hospital stay and zip code. The final algorithm assigns a very strong correlation between these last two features, which results in output depending strongly on zip code, while another feature, socio-economic status, has not been considered and is the feature influencing both length of hospital stay and zip code. This feature is called the confounder.
Figure 3: An example of confounder bias: the training data used for this algorithm contains multiple features per patient, including length of hospital stay and zip code. The final algorithm assigns a very strong correlation between these last two features, which results in output depending strongly on zip code, while another feature, socio-economic status, has not been considered and is the feature influencing both length of hospital stay and zip code. This feature is called the confounder.
What can we learn from this example of AI bias in healthcare?
This is a specific case where the confounder is not clear. A confounder is a different feature influencing both features you thought were connected. So instead of the hospital stay length (feature 1) being influenced by the zip code (feature 2), both hospital stay length and zip code were most likely influenced by socio-economic status (the confounder).
A moment of AI bias in healthcare contemplation
All three examples of AI bias in healthcare that are discussed in this article show how a bias can be ingrained into an algorithm, either by failing to select the right subjects for a dataset, or by having picked the wrong features for the algorithm to be trained. However, we should be aware there are also many situations where decisions are affected by bias introduced by the clinicians themselves or by the interaction of clinicians with an algorithm.
It may be clear that AI bias in healthcare remains a challenge, but with the right data selection and algorithm design, this challenge is not impossible to overcome. While we are at it, we should also very carefully think about what it is we want the algorithm to do. Aren’t we implementing our own way of thinking while AI offers the opportunity to create more objective ways to judge than the human mind can? Can we select the data and train the algorithm in such a way that we actually erase biases human thinking would introduce? The Amazon recruitment algorithm is an interesting example. We say the developers failed because the algorithm copied human behavior, but it shows how we can dream of an algorithm that makes a fairer decision than we do.

Bibliography
- Dastin, J. Amazon scraps secret AI recruiting tool that showed bias against women. (2018). Available at: https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G.
- CBTRUS. 2018 CBTRUS Fact Sheet. (2018). Available at: http://www.cbtrus.org/factsheet/factsheet.html.
- Gershgorn, D. If AI is going to be the world’s doctor, it needs better textbooks. (2018). Available at: https://qz.com/1367177/if-ai-is-going-to-be-the-worlds-doctor-it-needs-better-textbooks/.
- Fairness: Types of Bias. (2019). Available at: https://developers.google.com/machine-learning/crash-course/fairness/types-of-bias.
- Lashbrook, A. AI-Driven Dermatology Could Leave Dark-Skinned Patients Behind. (2018). Available at: https://www.theatlantic.com/health/archive/2018/08/machine-learning-dermatology-skin-color/567619/.
- Wood, M. How algorithms can create inequality in health care, and how to fix it. (2018). Available at: https://medicalxpress.com/news/2018-12-algorithms-inequality-health.html.