The currency of the 21st century may be data instead of dollars, euros or Yens. With AI being on the rise and with all the opportunities this offers to improve many processes, this is no less true in the healthcare industry. Hence it is not an unreasonable thought to think that all the data gathered in hospitals is extremely valuable, which, on a fundamental level, is very true. However, all these test results, medical images, patient statistics, etc. most likely still need a lot of attention before they can put to work to create some game changing AI.
Suppose you have a PACS filled with medical images. Along with the images, there are patient data available: age, patient history, other test results. Extremely valuable information, but can you use this data right away to train your own algorithm? Or can are these dataset AI healthcare companies are dying to get their hands on? Good question, largely depending on what the data exactly contains, how it is organized and what the eventual goal of a computer algorithm is that is meant to be developed with it.
This article will discuss the necessary steps to complete to prepare an AI radiology dataset for training which will make the dataset a rare one in its kind: a complete, neatly structured, easy-to-work with dataset, fully ready for AI training.
Start with an initial AI radiology dataset
The process starts with figuring out which data you need and gathering this dataset. This process includes steps such as tailoring the dataset including labels to your specified use case, the right balance of variability and image quality in your dataset, amount of data, and quality of the labels. The details can be found in our article on data collection.
Do you have a batch of data ready? Great, let us guide you through the process of checking and sanitizing the data, which we call data cleaning, THE way to turn that big pile of data into a valuable dataset, ready to develop killer algorithms. What are the important steps you need to take care of to make sure the dataset is all neat and clean before algorithm training can start?
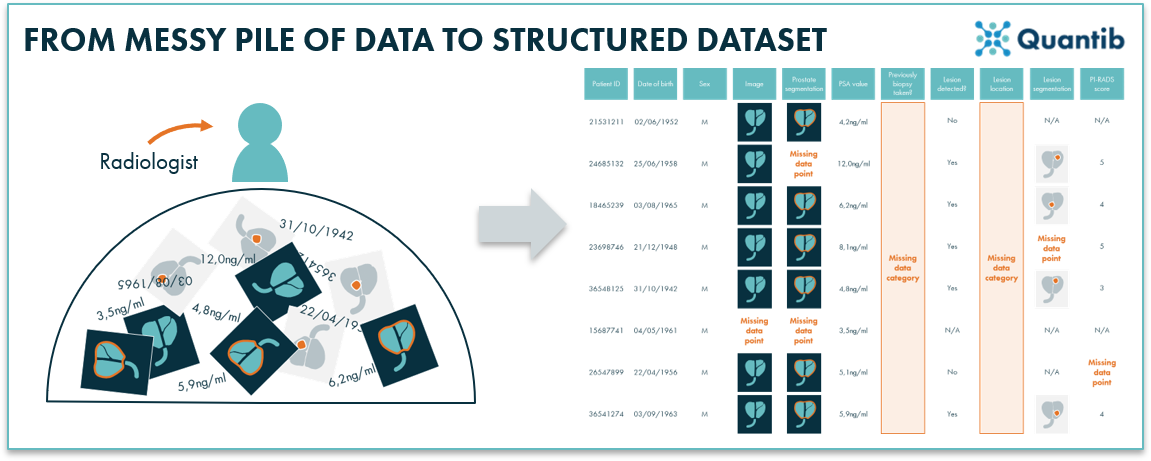 Figure 1: Hospital data is often unorganized and therefore unfit for direct algorithm training. Applying structure and creating a well-organized overview of the data will help prepare for next steps in building an AI algorithm.
Figure 1: Hospital data is often unorganized and therefore unfit for direct algorithm training. Applying structure and creating a well-organized overview of the data will help prepare for next steps in building an AI algorithm.
Is the AI radiology data complete?
The easiest way to start this exercise is with a checklist: which data is needed for the algorithm you have in mind? If you are planning to collaborate on this with an AI radiology company, be sure to involve them while creating this list. Look at which sequences are required, e.g. only a T1-weighted image, or also a T2-weighted image. Consider the data labels, for example, a segmentation file, parameters obtained from the patient records or a simple recording of benign/malignant. If one of these are categories of data is missing or there are just gaps within certain categories (a few patients are missing the T1 scans, others miss the segmentation, etc), there are several options to make sure the dataset can be completed. Firstly, you can try to track down the missing data, dive into hospital systems, check for records you might have missed before. However, it is of course possible the data was just never created, because nobody entered it into the system. In that case, it might be possible to create that data yourself. By which we do not mean that you take an afternoon to come up with some random numbers, but get experts to complete the dataset. For example, are segmentations missing? Hire a radiologist to draw the segmentations. Usually completing a dataset in such a way requires a lot of time though, from specialized people.
But, fred not, there are still two options left. Option one: exclude the data entries that are incomplete. A popular approach, however, obvious downside is that it can drastically reduce the size of the data set if many entries miss one or more labels or input parameters (and unfortunately, this happens quite a lot in healthcare). Alternatively, an algorithm that can handle missing data can be used. A missing label such as a blood value can for example be replaced by the average, or predicted for that patient based on their other parameters. Of course, this will be less accurate than the actual measurement, and missing images are quite challenging to replace. Other algorithms are designed in such a way that they have smarter, more complex ways of dealing with missing datapoints.1
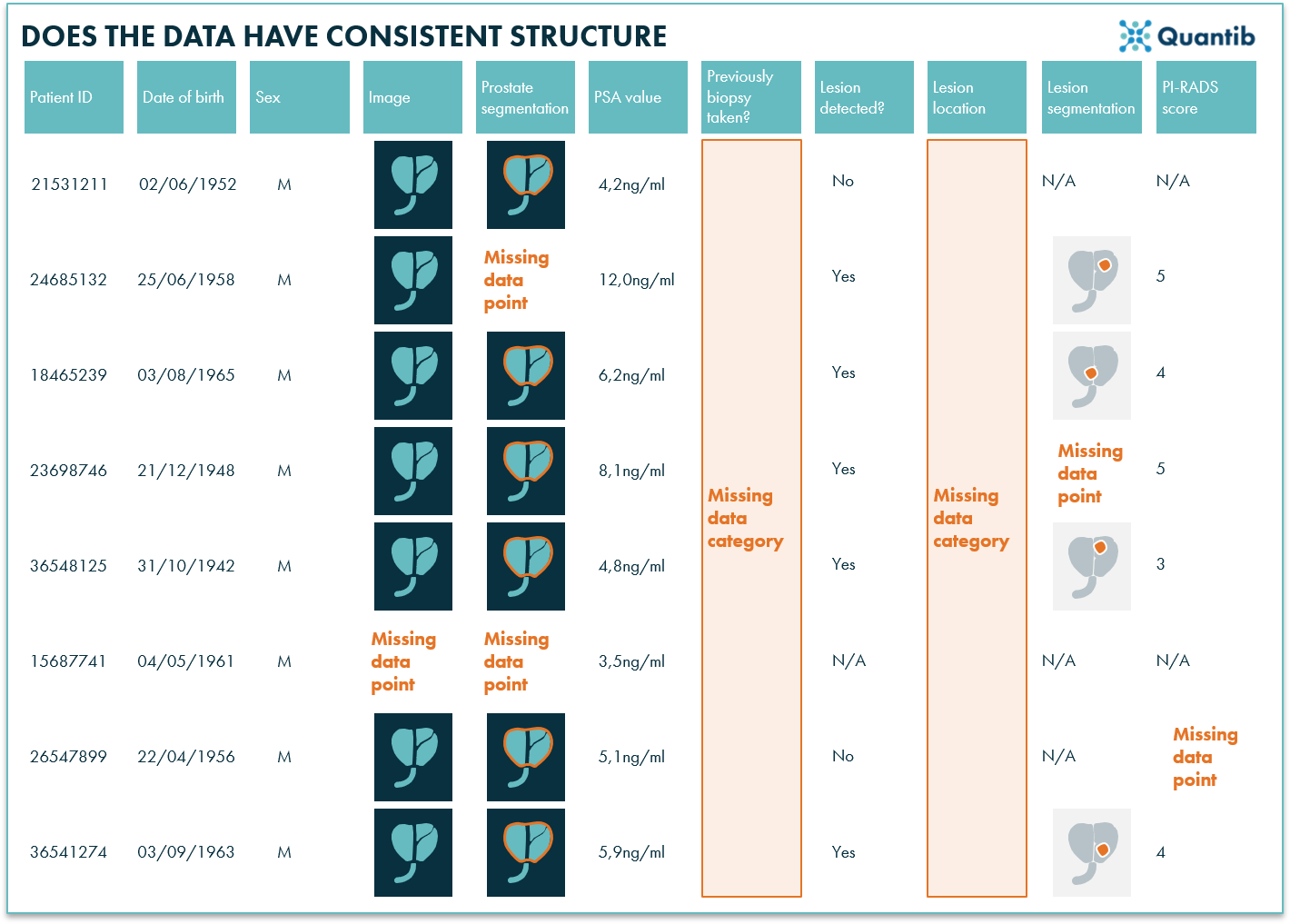
Figure 2: Some data may still be missing in the dataset. Depending on the output the algorithm needs to provide, it can be crucial to fill those gaps.
Does the AI radiology data have a consistent structure?
Once you have a dataset with complete information, you need to make sure it is stored in a consistent way, so that it can be processed by the (processing and training) scripts. Some segmentations may be stored in one file format, and others in a different format, for example because they have been created with a different software package or version. Datasets acquired at different MRI scanners may be stored in a different way, or use different DICOM tags; one radiologist may have indicated a certain parameter in one way, and another radiologist in another; etc… What you want, is the same structure for each case, so that a computer can understand how to read the data. Think of it as a nice excel table with neat columns that contain the same type of info for each data entry. The most common solution is to write a data preparation algorithm that is able to read each available type of data, and convert to one consistent format. Other options would be to use readily available conversion software tools, or open and process each file or parameter manually (good luck with that!).
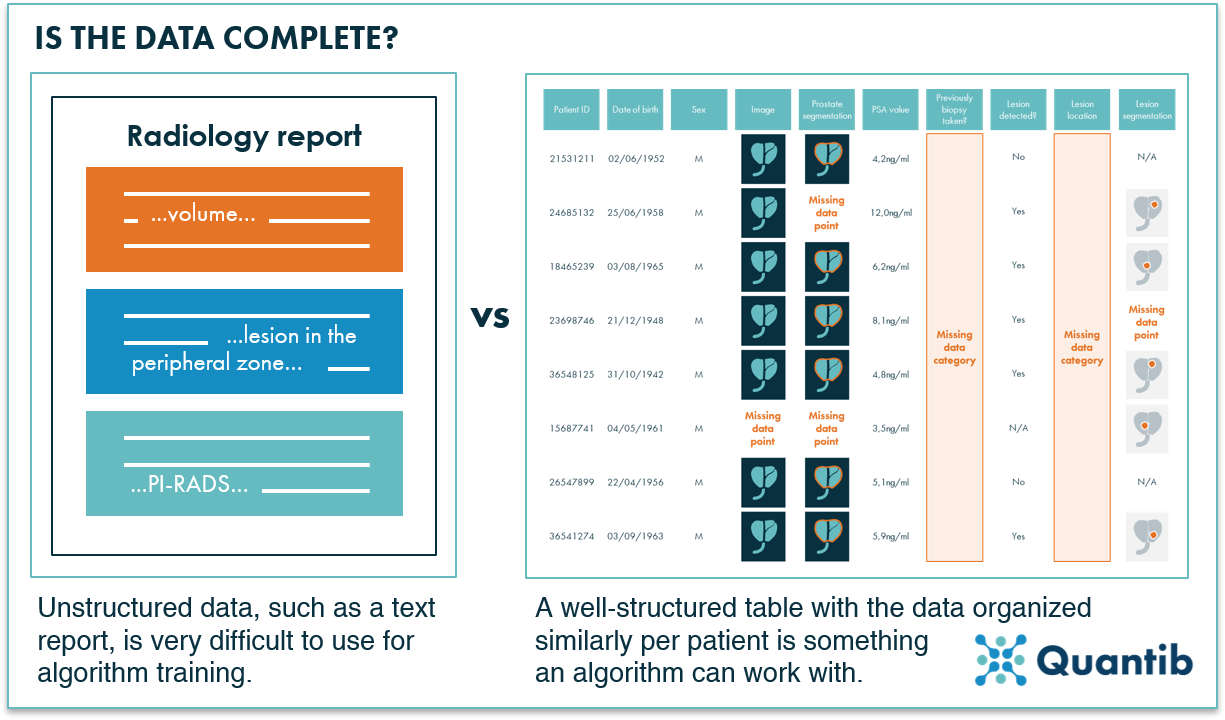
Figure 3: AI algorithms have a hard time dealing with unstructured data such as text reports. Organized data in a structured format, is ready to use for algorithm training.
Does the AI radiology data have the right input format?
A second type of consistency relates to the data acquisition parameters. We noted in the [previous blog] that if you want your algorithm to be able to handle data acquired at different resolutions or different settings, you need this variation in your training set. But this does not mean that you have to give this data as such to the algorithm. You may for example train an algorithm that needs a specific size image, and expects the organ of interest to have a certain size in this image. Then you probably want to resample all input images to the same resolution before you feed it to your training algorithm. Usually this is fine, but you need to remember that you will need to apply the same preprocessing steps when you apply your trained algorithm to new unseen datasets.

Did you check the AI radiology data for errors?
Now you have a dataset for which each entry is complete. Does this mean you are done? Most likely the answer is no as many datasets still contain some errors here and there. Some of these errors may be debatable. For instance, errors that relate to inter-observer variability (Which observer was “wrong” and which one was “right”?) and errors in the ground truth labels that were used (Are the accurate enough? What is actually the real “truth” in this specific situation?) The same holds for artefacts in the images. You could argue these are errors, as it does not represent what was really there in the body and what you wanted to see in the image. However, in clinical reality artefacts occur in medical images. Hence, an algorithm that is able to deal with those is significantly more useful than one that only works for perfect medical images. The question is: do you want to include all artefacts? Making it a lot harder to train a decent algorithm. To delete the most difficult artefacts from your dataset, but leaving some so the algorithm will learn how to deal with those, you may need to inspect all datasets manually.
Are you dealing with a very large dataset? Then maybe you want to take a more pragmatic approach, for example, by manually inspecting outliers. The outlier cases can be selected many different ways; it is possible to have a look at the cases with the largest and smallest segmentation volumes, drop cases that have “lesions” segmented outside of the organ you are interested in, filter out cases that have or unrealistic values otherwise (e.g. sky-high PSA values that must have been submitted wrongly). The downside of this approach is that you have to come up with this list of possible errors, before you can check and tick off.
So is my AI radiology dataset fool proof now?
In the end, what you want to have after this step, is a cleaned dataset. It should be complete and consistent for each case, should not contain any errors anymore, and it should be stored in such a format that the training code has no problem reading it. Therefore, during the entire process it is best practice to keep in mind what your training code is expecting in terms of file formats and parameters. Converting your whole dataset from DICOM to Nifti before feeding it into the algorithm is something you would rather avoid.
Additionally, make sure to check whether the algorithm has a build in resampling step making sure all images will be turned into the same size before the real AI magic is performed. If not, the images in the dataset should be adjusted to the right size before providing them to the algorithm.
Each of these steps can be accelerated and done more efficiently by automating checks and letting a computer do the work. However, let’s not create false expectations: setting up the computer to do the work also requires additional algorithm creation, plus most likely these check-algorithms will still encounter situations that they do not know how to handle, hence manual inspection will still be needed for some cases.
And before you share, is the AI radiology data anonymized in the right way?
Yes, anonymization is crucial in healthcare context. Patient data is sensitive information that should not be shared with just anyone. However, be sure not to be too rigorous. Some data that may seem privacy sensitive, is actually needed to train the algorithm in the right way. For example, erasing the age of the patient might be something you will come to regret it later on, if age turns out to be a useful feature for the algorithm to leverage during training. PACS systems often have anonymization methods which are convenient to use, but make sure to check what information you need to keep and what the system will delete before applying the PACS anonymization to the whole dataset.
In conclusion
Cleaning a dataset is hardly ever a quick and easy task. However, it is unavoidable if you want the eventual algorithm to provide you with any usable answers. Hence it is extremely valuable to have a neat, clean and structured dataset, whether it is for training your own algorithm or you want to collaborate on a project with an AI radiology company.

Bibliography
- Warner, J. How-to Guide to Handling Missing Data in AI/ML Datasets. (2018). Available at: https://datafloq.com/read/how-to-guide-handling-missing-data-ai-ml/4821. (Accessed: 28th October 2020)