The application of deep learning in radiology is on the rise. Especially over the past 5 years, applying deep learning to medical imaging problems has taken flight. Recently, artificial intelligence techniques, including deep learning, have been increasingly deployed into clinical applications. One of the very first deep learning-based applications approved for clinical use was the retinopathy detection software IDx developed and for which they received a lot of attention from the media.1 However, deep learning is also deployed by many other radiology applications, such as GE Healthcare’s image reconstruction system for CT.2 Convolutional neural networks (CNNs) are certainly the most popular technology for both medical and regular image analysis problems. These deep neural networks are specifically designed for image analysis and are very good at detecting objects and classifying images. So, it is no wonder they are often deployed to tackle radiology challenges, but how does such a network actually work? And why are they so suited for medical image analysis?
Deep learning in radiology methods: What is a convolutional neural network?
To understand convolutional neural networks, we first need to take a look at the very basics of deep neural networks. Simply put, a deep learning-based algorithm works in the following way: input data enters the deep neural network through the input layer. Here,the input data format gets adjusted in such a way that the deep neural network knows how to process it and possibly some additional calculations are performed. Then, the results are passed on to the first hidden layer. You should think of such a layer as sort of a way station where data comes in and calculations are performed. A network can contain multiple hidden layers, meaning that this step performing a calculation and passing on the outcome to the next hidden layer is executed multiple times, until the output layer is reached. The function of this final layer is simply to give the answer to the question the deep neural network is supposed to answer. For example, in figure 1, the input is a prostate MR image which passes through the network with all its layers, and the output layer delivers the answer to the question “Does this prostate MR image contain a lesion?” If you are looking for a more detailed explanation on deep learning in medical imaging, please visit our blog on deep learning in radiology.
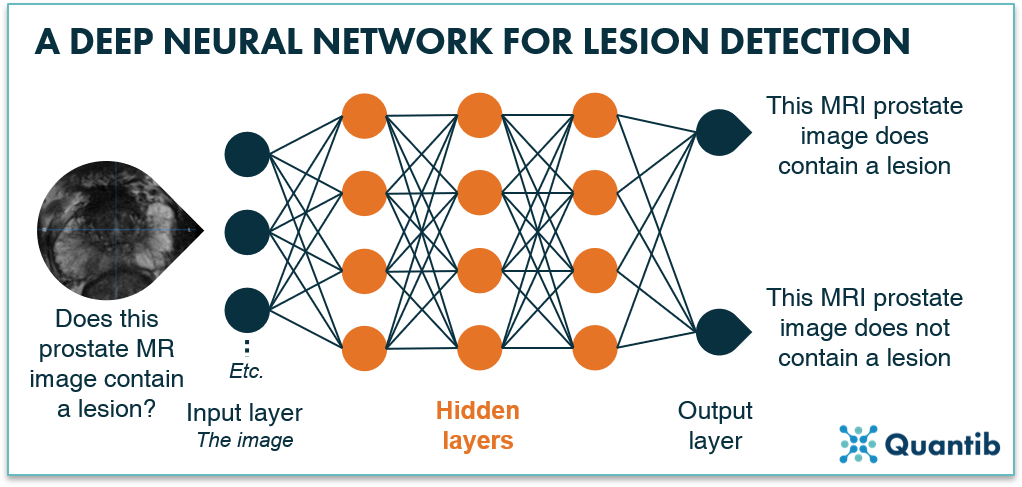
Figure 1: A deep neural network uses multiple layers to process input data (in this case a prostate MR image). After the data passes through the network, the algorithm provides an answer to a specific question, e.g. does this prostate MR image contain a lesion?
Now what is so specific about a CNN? It is actually the way the network layers perform the calculations based on a mathematical operation called convolution, hence, the name, convolutional neural network.
How does a convolutional neural network in medical imaging work?
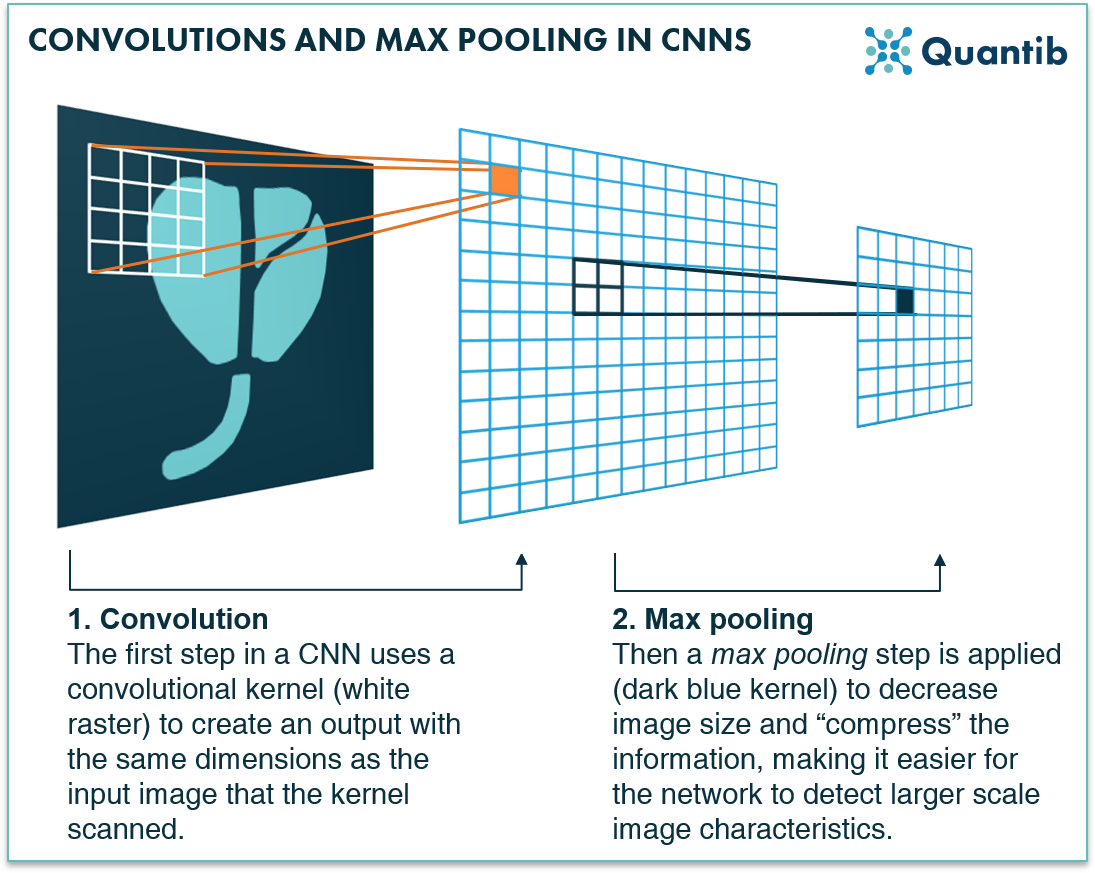
Convolutions use a kernel to determine the output that should be communicated from one layer to the next. A kernel is actually nothing more than a raster, such as shown in figure 2 (the kernel is shown in white). In this case, it is a 4 by 4 kernel, meaning it interacts with an area of 4 by 4 voxels in the image for each step it takes. Yes, for each step, because a convolution is carried out step-wise: the kernel “scans” the image step-by-step, every time performing a calculation of which the result will be stored in a new grid (blue in figure 2). This grid filled with results is passed on to the next layer: input for the following series of calculations.
.png?width=1562&name=1%20(1).png)
Figure 2: A convolution-step in a deep neural network uses a kernel, a raster, that scans an image voxel by voxel and performs calculations. The outcome to these calculations is the input for the next layer in the network.
You can imagine a lot depends on what this kernel looks like. How do you get the right kernel for a specific layer in the CNN? The wonderful thing about a CNN is, it automatically designs the kernel during the training phase. This process uses the input data to determine what the kernels for each layer should look like to detect specific image characteristics (e.g. shapes, intensity, textures, contrast, etc.).
Once the network is trained, it is ready to put the kernels to work and have them perform convolutions. The calculation that a convolutional kernel performs for each voxel is actually a matrix multiplication (which comes down to multiplying the values in the image with the values in the kernel and then summing them up). The convolution will provide a high output when the kernel is at a spot that coincides with the shape it is searching for. Have a look at figure 3 for a visual example.
-1.png?width=1824&name=1%20(2)-1.png)
Figure 3: Firstly, a kernel is defined that is sensitive to detecting specific imaging characteristics such as certain shapes in an image. Secondly, the kernel scans the full image. It will provide a high output when it is at a spot where a specific imaging characteristic manifests itself very strongly. Please note, for simplicity’s sake, this example uses a kernel that only consists of zeroes and ones. However, usually, kernels use other numbers as well to make the kernel more sensitive in certain areas than in others.
Since the kernel passes through the entire image and provides an output for each voxel, it can detect an object in every corner of the image. In other words: similar objects will have similar outputs independent of their location in the image. It is, however, possible to store the location where a kernel has a high output, so you know where in the image the object was found.
What is max pooling and why does a CNN for deep learning in radiology need it?
Our example above is about detecting a prostate gland, a fairly large shape in an image. Usually, a CNN first tries to find smaller objects and then larger ones. Why? This has everything to do with max pooling.
It is not hard to imagine that computations can get very extensive and will therefore require a lot of processing time. The larger the image and the larger the kernel that is used, the bigger this problem gets. Using a max pooling layer helps solve at least part of it.
What does a max pooling layer do? Actually, this is one of the simplest operations an algorithm can perform. It looks at a part of the image, say an area of 2x2 pixels, in the image and it takes the maximum value, which is passed on to the next layer. Hence, a 2x2 area in the original image is then represented by only 1 pixel, i.e. each dimension is reduced to half of its size. In other words, the image gets smaller, resulting in less processing time for the next step that is performed in the next layer of the neural network. A CNN usually performs a convolution followed by a max pool, then another convolution and another max pool. Hence, the size of the image decreases with every step.
What are the main deep learning in radiology tasks a CNN is ideally suited for?
Detection
Classification
Segmentation

Are CNNs the future?
Bibliography
-
Stark, A. FDA permits marketing of artificial intelligence-based device to detect certain diabetes-related eye problems. (2018). Available at:https://www.fda.gov/news-events/press-announcements/fda-permits-marketing-artificial-intelligence-based-device-detect-certain-diabetes-related-eye. (Accessed: 19th August 2020)
-
Steinhafel, M. GE Healthcare Announces the First U.S. FDA 510(k) Cleared Deep Learning Based CT Image Reconstruction Tech. (2019). Available at:https://www.ge.com/news/press-releases/ge-healthcare-announces-first-us-fda-510k-cleared-deep-learning-based-ct-image. (Accessed: 19th August 2020)