Until a few years ago, conventional image analysis was based on the careful handcrafting of features by humans that captured the relevant aspects of the image for the task at hand. This approach has now been completely overthrown by the advent of deep learning. This technique is helping overcome challenges in medical image processing, however, it is important to understand the obstacles that still exist to enable solutions.
Also, in the realm of medical image analysis, deep learning is rapidly gaining ground. Research groups increasingly apply deep learning, and radiology AI companies are starting to implement the first deep learning software meant for practical use in the clinics. Since a few months, the FDA is starting to hand out clearances and approvals for deep learning based software. For example, IDx-DR, a software that detects diabetes-related eye problems, received FDA clearance earlier this year, paving the way for other companies applying artificial intelligence to medical images.1
The fascinating ability of deep learning radiology to interpret pictures
Looking specifically at image classification, the task of labeling an image based on its content, current deep learning based performance is very impressive. The ImageNet project offers a very large database of over 14M pictures in different categories. All pictures are labelled, making the database a valuable tool for the training of artificial intelligence algorithms. Each year, ImageNet organizes a challenge for which participants develop an image classification algorithm. The assignment is to label images by selecting from a set of 1000 potential labels. Submitted algorithms are considered successful if the correct label is in the provided top five of labels. Typical examples are shown in the figure below.2

Figure 1: Results of the ImageNet image registration challenge.
The correct label is provided directly underneath each image. Below that, the list of top five suggestions by the algorithm is given with their relative confidence. Looking at the first row, we observe four examples where the algorithm’s first suggestion was correct. Note how the pictures are not carefully cropped and potential categories go from mites to ships to scooters, and the algorithm is still able to determine what is in the picture. The first two examples on the second row show a slightly less successful performance: the correct label is part of the five suggested labels, but not the first one on the list. However, for the first image, the algorithm suggested a convertible with most confidence, which is a perfectly defendable guess for that image. The final two images, the algorithm officially got wrong, but even then: for the first of those, it suggested “dalmatian” which is clearly part of the image and for the second, it is struggling with specific monkey sub-types, which many humans would probably end up confusing as well. The winning algorithm of the ImageNet challenge only has a 6% error rate in labelling images overall.

Two reasons deep learning radiology recently took flight
Deep learning is based on thinking about neural networks that have been around since the 1940s. It was originally inspired by the basic structure as observed in human brain structures. Until recently, these networks were not powerful enough to be used on image classification tasks. However, 2 key developments took place over the past years - explaining why this technology has taken flight now.
Firstly, there has been an explosion in the amount of data available. The development of the digital camera, and, more recently, the smartphone, are responsible for this data boom. Combined with the ability to aggregate all these newly available pictures using the internet, we now live in a world where deep learning experts have a countless quantity of material to work with.
Secondly, developments in processor architecture have allowed a massive speed up of mathematical matrix operations. Scientists realized the math underlying 3D scene calculation for computer gaming was similar to matrix operations and needed to implement neural networks. Hence, the Graphics Processing Units (GPUs) optimized for gaming can also be leveraged for neural networks. With increased computational power, neural networks can increase significantly in size - adding to their expressive power as models. This expansion is done by adding “layers”, inspiring the name deep learning.
Why hasn't deep learning radiology taken over medical imaging... yet?
The developments described above led to a rapid improvement and impressive results of deep learning applied to simple 2D pictures. Achieving the same levels of performance in the medical imaging domain is still a work in progress due to three primary challenges in medical image processing using deep learning.
3 Challenges in deep learning AI
- A first inhibiting factor is the access to large high quality labelled datasets for training. The ImageNet database is extremely powerful, because it is huge and accurately labelled. Comparing the typical medical imaging dataset in the figure below to a database like ImageNet, the volume available is clearly still several orders of magnitude behind.
A technique called augmentation could be able to help solve that problem. Using augmentation, scientists are able to double, triple, or even quadruple datasets by modifying the available images in a way that new images are created, which still show the same characteristics, but are slightly different and, therefore, seen as “new training material” by the neural network. 3 - In addition, the most successful deep learning models are currently trained on simple 2D pictures. CT and MRI images are usually 3D, adding, literally, an extra dimension to the problem. Conventional x-ray images may be 2D, however, due to their projected character, current deep learning models are not adjusted to these either. Experience needs to be gained with applying deep learning to these types of images.
- Finally, the non-standardized acquisition of images is one of the biggest challenges in medical image processing. The more variety there is in the data, the larger the dataset needs to be to ensure the deep learning network results in a robust algorithm. A method to tackle this barrier is to apply transfer learning, which is a pre-processing technique aimed to overcome scanner and acquisition specifics.
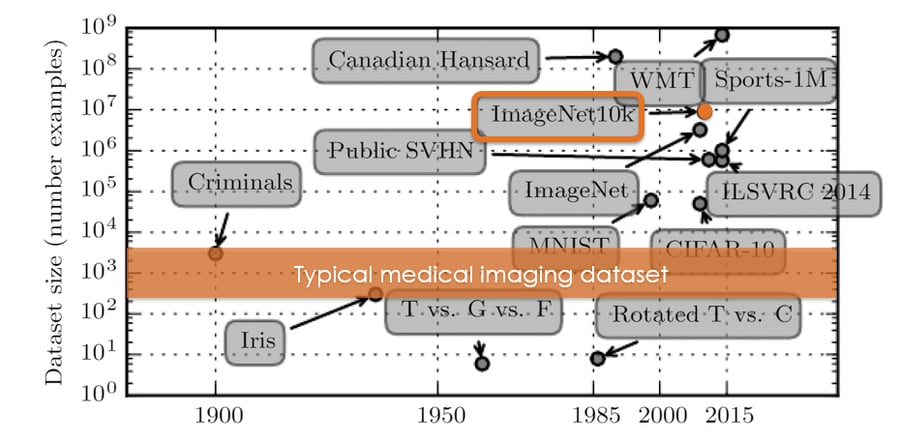
Figure 2: ImageNet currently contains around 14 images, whereas a typical medical imaging dataset usually does not exceed a few thousand images. The image is adapted from: Deep Learning: Ian Goodfellow, Yoshua Bengio, and Aaron Courville - MIT press.4
How 'deep' can we go with deep learning radiology?
Deep learning will strongly influence the practical reality of medical image analysis. In the (near) future, current challenges in medical image processing will be solved. Companies start applying it and the first deep learning based products are coming off the assembly line. It will take some time as there are still challenges on the road ahead. Sizes of medical image datasets need to increase, either by aggregation or by augmentation. We need to gain more experience with 3D images, and the medical community needs to standardize image acquisition. However, deep learning networks will become better and better at recognizing deviations on images, making them a great tool for everyone analyzing medical images in the future.
Curious for more information on artificial Intelligence in radiology? Subscribe to our blog using the form on the right!

Bibliography
- FDA permits marketing of artificial intelligence-based device to detect certain diabetes-related eye problems. (2018).
- Colyer, A. ImageNet Classification with Deep Convolutional Neural Networks. (2016). Available at: https://blog.acolyer.org/2016/04/20/imagenet-classification-with-deep-convolutional-neural-networks/.
- Wang, J. & Perez, L. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. (2017). Available at: http://cs231n.stanford.edu/reports/2017/pdfs/300.pdf.
- Goodfellow, I., Bengio, Y. & Courville, A. Deep Learning. (2016).