As a radiologist, you might come across tasks that you would not mind handing over to artificial intelligence (AI), either because they are of a repetitive nature, prone to false positives/negatives, or because they take up a lot of your valuable time. While there are many companies developing AI-based algorithms for radiology, these vendors do not provide solutions for every existing use case. So what if you come up with your own idea for a killer radiology AI app that is not available and no one is developing it? In that case, you might decide to initiate the development of a new AI application yourself. As you probably realize, this is not an easy task and you may want to collaborate with parties that have vast knowledge and experience in the field of AI software development. Since data is the basis of every radiology AI algorithm, we want to help you get started and provide a set of handlers for radiology data collection. Additionally, since radiologists are working with this data every day, they play an important role in radiology data collection and curation.
Two starting points for a radiology AI algorithm idea
How to start? There are two possible starting points to kick off the development of a new radiology AI algorithm: a readily available dataset, or (an idea for) an application. Often, there are large datasets being stored on hospital servers that would be great sources of data for AI algorithm development. If this is your starting point, the selected dataset automatically defines which use case the algorithm will be focusing on. The alternative is the other way around: you have a specific use case in mind and need to gather the required data. Although collecting the data will not be an easy task, starting with a specific use case will allow you to pinpoint the exact data you need. This way, the algorithm will suit your needs perfectly. Of course, in the end, both aspects are crucial: you do not want to spend time and effort on developing an algorithm that no one is interested in, and you will not be able to develop a groundbreaking piece of technology if you do not have data.
Selection criteria when hunting for radiology AI training data
No matter the starting point, the data needs to meet certain criteria to create a useful algorithm. Although the specific criteria heavily depends on the context, there are some general guidelines to consider. However, before diving into collecting data or refining the dataset you started with, it is crucial that you have a use case defined. This comes down to defining in detail what the algorithm should give as an output. As an example, let’s take the case of prostate cancer. Should the algorithm locate a tumor? Should it segment the tumor and provide its volume? Should it provide the region the tumor is located in? Should it return a tumor grade? The type of data needed strongly depends on the answers to these questions.
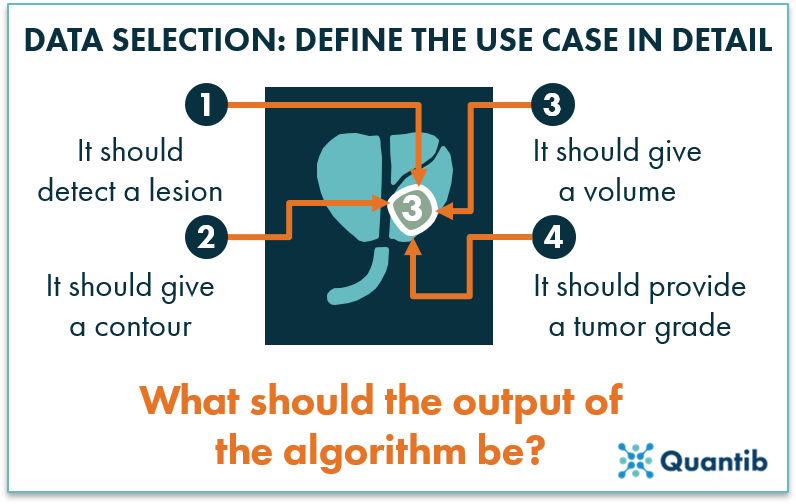
Figure 1: Before gathering the right data for a radiology AI algorithm, define the use case in detail and determine what the exact output should be.
Heterogeneous or homogeneous radiology AI datasets?
One can imagine that if a dataset only contains images obtained with a single acquisition protocol, on a single scanner, from one hospital (i.e. the dataset is very homogeneous), we cannot expect the algorithm to perform well on images acquired differently on another scanner. On the other hand, if a dataset contains images obtained with a large variety of acquisition settings and scanners from different vendors (i.e. the dataset is very heterogeneous), it is much harder for the algorithm to detect specific disease characteristics in an image, since not all variation between the images is disease related. In order to avoid this problem, it is important to cover the variety that you see in clinical practice – both image-wise and patient-wise. For example, if you want to develop and evaluate an algorithm to diagnose osteoarthritis of the hip on X-rays, it is important to gather a dataset of patients obtained with the acquisition protocol to diagnose osteoarthritis, not of children who fell off their bike and got an X-ray in the ER to check for broken bones. However, you do want to cover both male and female patients as well as the contrast range seen in the clinic. Otherwise ,you risk introducing unwanted biases into your algorithm.
Alternatively, if the images show a very large variation, there might be much to gain in standardizing the image acquisition protocol before you start trying to develop an algorithm that can handle multiple acquisition protocols, although it is not always an easy route to take.

Figure 2: While gathering the training data, be sure to select a dataset with the right level of heterogeneity.
What level of image quality is needed?
A well-known saying in algorithm development is “Garbage in, garbage out,” meaning that if low-quality data is used to train the algorithm, it will be a lot harder to have it perform well at the end of the process. This is not unlike humans, who find it hard to interpret and learn from low quality images. So, should all images used for algorithm training have superior image quality? No, not necessarily. If you only provide the highest quality images, the algorithm will not be used to average quality data, as seen in clinical routine. Hence, the algorithm will most likely not perform well in a clinical setting. Therefore, balance is key. Select training scans that cover the entire clinical range of scans in terms of signal-to-noise ratio, contrast, etc. As a guideline, any scan that a radiologist would deem suitable to base a clinical decision on, with reasonable confidence, should be okay to use.

Figure 3: The quality of the images in the training set will determine the level of quality required for input scans for the eventual algorithm.
Any application-specific requirements?
After addressing image quality, there might be additional requirements for the specific use case you are focusing on. For example, if you want to track longitudinal changes, a dataset containing data from multiple time points is needed. In case you want to include different imaging modalities, you need to provide the data that fits this case.
Be aware that the more specific input requirements are made, the harder it will be to collect a suitable dataset for algorithm development. If you have specific requirements and a dataset available that only partly matches the requirements, instead of gathering a new dataset, it is also possible to extend the incomplete dataset. This can be done by creating new annotations, or in extreme cases, by contacting patients asking them to undergo additional scanning.
How much data do I need to build a radiology AI algorithm?
A standard answer to this question is “a lot," but how much is a lot? How much is sufficient? That depends on your application, but in general there are a few things to consider.
1) How specific is the use case?
If you want your algorithm to be able to answer a very general question, such as “What object does this image contain?”, which can then be answered with a car, dog, grapefruit, or any other object, you will need a huge dataset. Think millions of images. However, if you want to determine whether or not a brain MRI image contains a tumor, the dataset can be significantly smaller. It all depends on the specificity of the question you want to answer and how many potential answers there are. For example, if the algorithm is to return a tumor grade, the required dataset will be larger, as you will need sufficient examples for each grade category. After all, the algorithm has to be able to learn the characteristics of each tumor grade with a sufficient number of representative examples.
2) For which scanner and acquisition protocol should the algorithm work?
This strongly links back to our previous point about data heterogeneity. The more different scanner models and acquisition protocols the algorithm should be able to handle, i.e. the more heterogeneous your dataset is, the more data you will need to train a well performing algorithm. Conversely, a more specific application can be trained with a smaller amount of data. However, keep in mind that this will result in an algorithm that will only perform well within a limited scope.
3) For which patient population should the algorithm work?
In an ideal world, each algorithm would perform accurately independent of the person it is applied to. However, there are significant physical differences between different populations. If the algorithm is supposed to work for a diverse population, sufficient examples covering this diversity are needed. One solution that could help cover a wider range of populations is to gather data from different medical institutions.
4) What type of algorithm are you using?
Algorithms of specific types are more likely to overtrain. This means that the algorithm gets too familiar with the specific examples it sees during training, therefore it performs fantastically on extremely similar cases, but it under performs on cases that are slightly different. The main way to prevent overtraining is to add more heterogeneous data. However, some algorithms are more prone to overtraining than others. Generally, more complex algorithms in which more parameters are learned, need more input data. Deep learning algorithms are a great example of complex algorithms that need vast amounts of data, while most traditional machine learning techniques can suffice with less data. On the other hand, simpler algorithms are often less able to capture all clinical variation.
5) Additional requirements
As mentioned in the previous section, there may be several important additional requirements to keep in mind to assure you have the right data to realize the desired algorithm output. However, they will most likely increase the required amount of data. If you want to include follow-up analysis, longitudinal data is needed, i.e. more than one examination per patient. For algorithms that handle multimodality data, you need examinations of all imaging modalities involved, hence a larger total dataset.

So… how much data do I really need to build this radiology AI algorithm?
We still did not arrive at any concrete numbers or ways to perform a sample size calculation. Reality is, depending on the factors mentioned above, it is possible to develop an algorithm with tens of images that performs relatively well, or an algorithm that has trouble executing its task reliably even though thousands of examples were used for algorithm development, and all options in between.
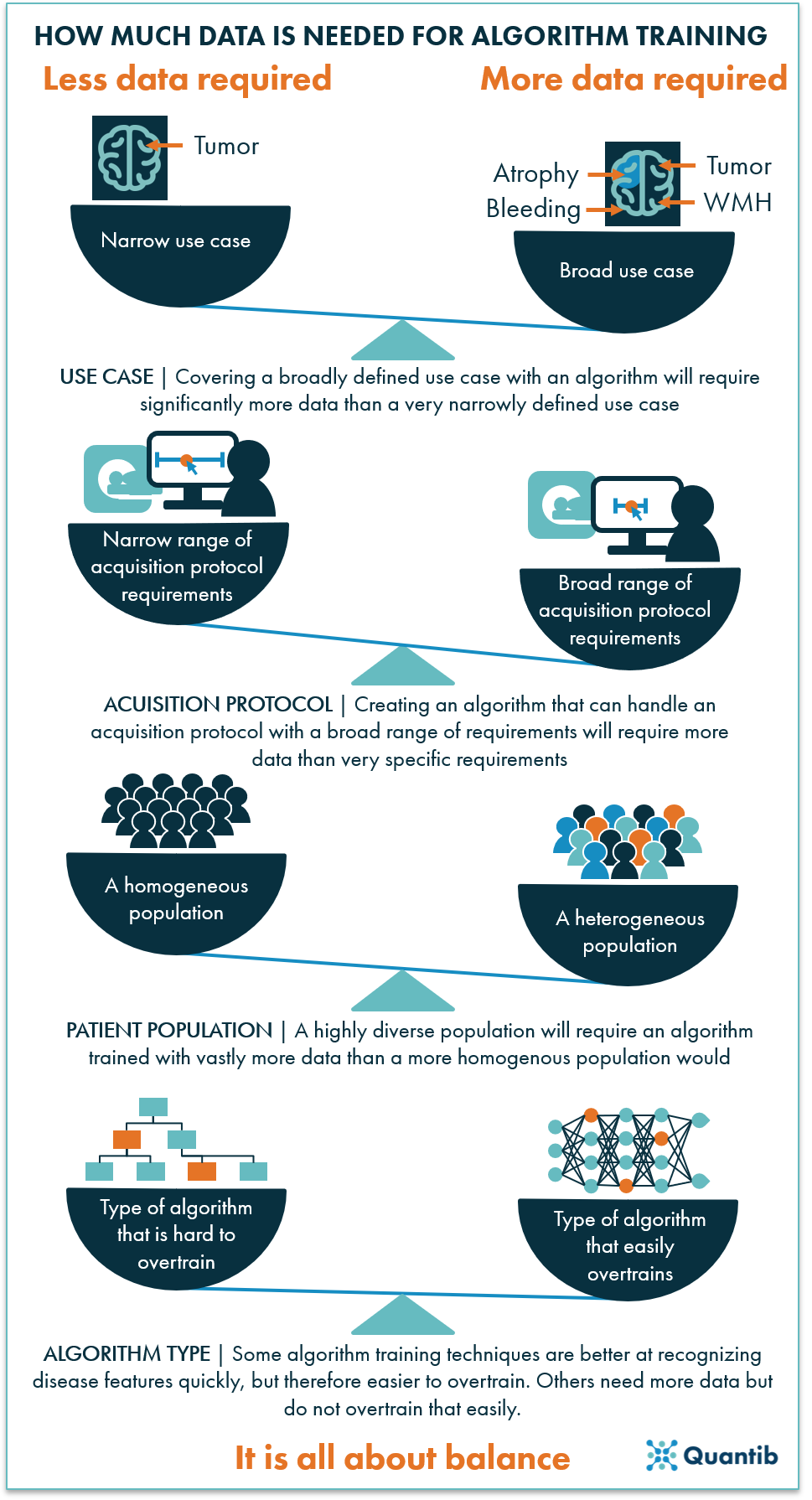
Figure 4: The amount of data needed to train a well performing algorithm depends on many factors. In the end, it is all about balancing the size of the dataset with the scope of the use case it can be applied to.
Radiology AI labels and their quality
In addition to the images, the right labels are a crucial aspect of the data. The easiest situation is the one where you have been performing the task you want to automate already on the dataset you selected, and you know where to find those labels. For example, if tumors have been graded and documented in the patient records.
However, in many cases, the situation is trickier. For example, if radiologists have documented the size of a tumor as ‘roughly a cm’ in a certain direction, while the algorithm should be able to determine the size exactly by segmenting the tumor and calculating the volume. In that case, what you are looking for is a precise segmentation of the tumor and the data may need to be relabeled. It could even be possible that the ultimate label, or ground truth, might in fact not be a radiological label, but perhaps a biopsy result.
While collecting or creating labels, it is also extremely important to think about who determines the labels and how many people are involved. For example, did medical students or best in class radiologists segment breast tumors? Did a single radiologist provide annotations or did you use an average of multiple experts? Keep in mind that your algorithm will never be able to perform better than the labels it has learned from. If the use case is more complex, i.e. involves a scenario where different radiologists often come to different conclusions, you may not want to reproduce the labels of a single radiologist. Rather than providing conflicting labels that will confuse the algorithm, it might be beneficial to bring a few radiologists together to come to a consensus about each case.
To conclude
Data collection is all about balance and using a representative set of examples that you expect to see in practice. If you have a very specific use case and you want to develop an algorithm that performs a simple task on a very homogeneous, high quality dataset in your own hospital, a relatively small dataset of tens of images might get you started. The more complex the use case gets and more widely applicable you want the algorithm to be, the more careful you need to think about the datasets you want to be able to train and evaluate, and the more data you need - likely hundreds or even thousands of datasets may be required.
